파일 시스템(FS)와 가상 파일 시스템(VFS)

파일 시스템
파일
파일에는 이름, 용량, 정보, 속성 등 여러 메타데이터가 저장되어 있다. stat ./Desktop 을 실행시키면 해당 디렉토리의 메타데이터를 조회할 수 있다.

| 항목 | 값 | 의미 |
|---|---|---|
| 16777232 | Device ID | 파일이 위치한 파일시스템(디스크)의 식별 번호 |
| 249482 | Inode 번호 | 파일을 식별하는 고유 번호 |
| drwx------ | 권한(permissions) | 디렉토리, 사용자만 rwx, 그룹/others는 접근 불가 |
| 15 | 하드링크 수 | 이 디렉토리를 참조하는 링크 개수 (하위 디렉토리 포함) |
| donghoon_kang | 소유자(owner) | |
| staff | 그룹(group) | |
| 0 | 파일 크기(size) | 디렉토리 자체의 데이터 크기 (macOS에서는 보통 0) |
| 480 | 블록(blocks) | 디렉토리가 사용하는 디스크 블록 개수 |
프로세스는 자신이 사용 중인 파일을 구분하기 위해 파일 디스크립터(file descriptor)정보를 사용한다.
파일 디스크립터는 운영체제가 특정 파일이나 입출력 자원에 부여하는 0 이상의 정수형 식별자이다. 이를 통해 프로세스는 시스템 콜을 호출하여 파일을 읽거나 쓸 수 있다. 기본적으로 파일을 다루는 모든 작업은 운영체제에 의해 이루어지기 때문에 응용 프로그램은 임의로 파일을 조작할 수 없으며 시스템 콜을 이용해야 한다.
보통 하나의 파일에 대해 입출력을 하기 위해서는 열기 > 읽기/쓰기 > 닫기 순서대로 API를 호출하게 된다.
open: 파일을 열기 위한 시스템 콜로, 옵션과 함께 호출되며 파일 디스크립터를 반환한다.O_WRONLY: 쓰기 전용O_CREAT: 파일이 없으면 생성한다.O_TRUNC: 기존 내용이 있다면 비우고 새로 작성한다.0644: 해당 파일의 권한을 설정한다.(rw-r--r--)int fd = open("example.txt", O_WRONLY | O_CREAT | O_TRUNC, 0644);
read: 열린 파일에 대해 지정된 크기만큼 데이터를 읽는다.fd에 해당하는 파일을sizeof(buffer만큼 읽어서buffer에 저장할 것이며, 실제 읽힌bytes를 반환한다.ssize_t bytes = read(fd, buffer, sizeof(buffer));
write: 해당 파일에 데이터를 쓴다.write(fd, "Hello!\n", 7);close: 열려있는 파일을 닫아, 파일 디스크립터를 반환한다.close(fd);디렉터리
파일과 다른 디렉토리를 포함할 수 있는 컨테이너이며 계층적으로 구성된다.
- 계층적 트리 구조
- 경로
- 절대 경로: 루트 디렉토리에서 자신까지 이르는 경로
/home/kang/test.js
- 상대 경로: 현재 디렉토리에서 자신까지 이르는 경로
./test.js
- 절대 경로: 루트 디렉토리에서 자신까지 이르는 경로
운영체제에서는 디렉터리를 특별한 파일의 종류로 간주한다.
그렇다면 어떻게 디렉터리에 저장된 데이터를 확인할 수 있을까?
디렉터리 엔트리(Directory Entry)는 테이블 형태로 각 엔트리에 디렉터리에 저장된 대상의 이름과 실제 보조기억장치에 저장된 위치 등을 저장한다. 파일의 속성들을 명시하는 경우도 있다.
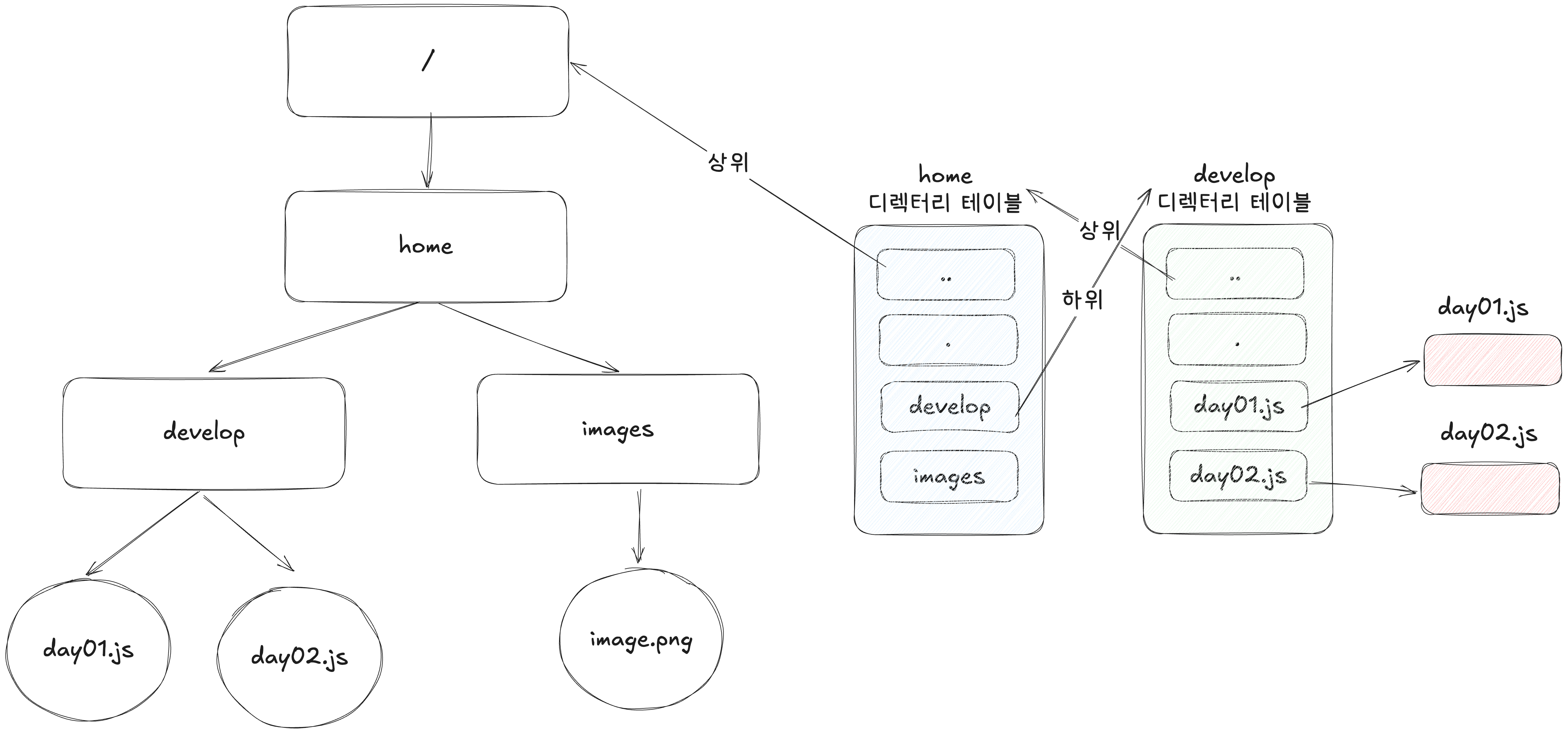
이러한 구조를 가진 파일 계층 구조가 있다면 각 디렉터리들은 디렉터리 테이블을 갖게된다. ..는 상위 디렉터리를 가리키며 .은 현재 자신의 디렉터리를 가리킨다. 디렉터리 혹은 파일을 통해 하위 계층으로 내려갈 수 있으며 ..를 통해 상위 계층으로 올라갈 수 있다.
파일 시스템 종류
운영체제별로 지원하는 파일 시스템의 종류가 다르다.
| OS | 파일 시스템 |
|---|---|
| Windows | NTFS, FAT32 |
| Linux | ext2/3/4, XFS, Btrfs |
| macOS | APFS, HFS+ |
리눅스는 미닉스에서 영감을 받아 개발이 시작되었으며, 기존 미닉스의 파일 시스템이 갖고 있던 한계들에 대응하기 위해 ext가 개발되었고 현재 ext4까지 발전해왔다.
아래는 ext2 파일 시스템의 구조를 설명한다.

하나의 파일시스템은 Boot block과 여러 Block Group으로 구분되는데, 동일한 파일에 대해 하나의 블록 그룹 내부에 저장하는 것이 조회 및 쓰기에 더 효율적이기 때문이다.
- 하드디스크의 헤더가 움직이면서 파일을 조회해야 하는데, 동일한 블록 그룹에 위치한다면 헤더의 움직임이 줄어든다.
하나의 블록 그룹은 또 여러 단위로 분리될 수 있다.
Super Block: 파일 시스템 전반의 핵심 정보들을 담고 있다.- 마운트된 파일 시스템 구조에 관한 정보를 제공한다.
- 마운트(Mount): 디스크의 파일 시스템을 특정 디렉토리로 연결하여 사용 가능하게 만드는 행위
- 파일 시스템을 마운트하면 VFS는 파일시스템으로 부터 전달받은 super block 을 통해 초기화 된다.
block bitmap / inode bitmap: inode table과 data blocks 내 빈 공간의 위치를 빠르게 파악하기 위해 존재한다.- 0과 1로 표시하여 해당 번호의 데이터 존재 여부를 빠르게 파악하여 할당하게끔 도와준다.
inode table: inode 를 관리하는 테이블이며 inode는 하나의 파일에 대한 정보를 저장한다.data blocks: 실제 파일에 대한 내용을 저장하는 공간이다.
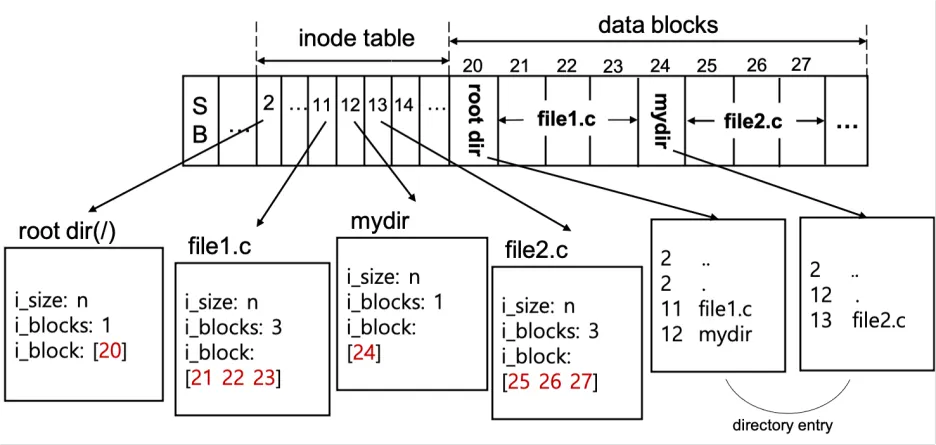
root dir은 20번의 블록 데이터를 갖는다.- 20번 블록은 11번 inode의
file1.c파일과 12번 inode의mydir폴더를 갖는다. - 11번 inode는 21,22,23의 블록 데이터로 분할되어 저장되어 있다. (
file1.c) - 12번 inode의
mydir폴더는 24번 블록 데이터를 갖는다. - 24번 블록은 13번 inode의
file2.c를 갖는다. - 13반 inode는 25,26,27의 블록 데이터로 분할되어 저장되어 있다. (
file2.c)
가상 파일 시스템
운영체제별로, 운영체제 내에서의 파일 시스템 별로 동작하는 방식이나 메타데이터 구조, 디렉토리 관리 방식이 모두 다르기 때문에 응용프로그램 입장에서는 매번 파일 시스템과 관련된 구현 세부 사항을 신경쓰며 관리하기가 어렵다.
그렇기 때문에 하나의 공통된 인터페이스를 제공하여 여러 파일 시스템에서도 동일하게 동작하게끔 만들어주는 것이 가상 파일 시스템(VFS)이다.
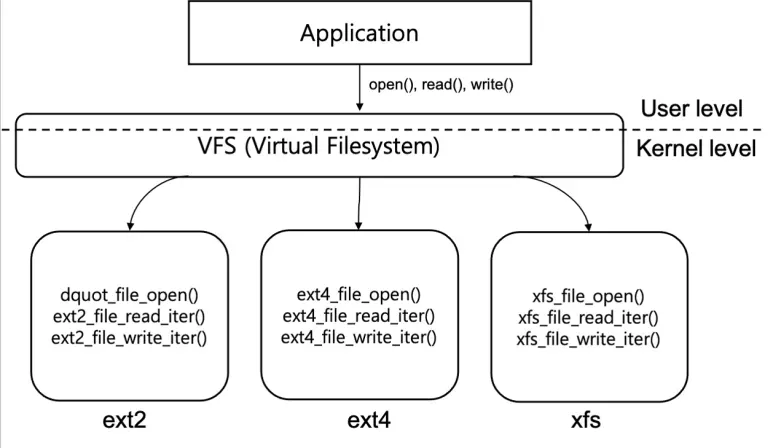
VFS는 파일 시스템을 추상화하여 open(), read(), write()같은 공통 인터페이스로 다양한 파일 시스템의 함수를 대체하여 사용할 수 있게 되었다.
open(),read(),write()등의 시스템 콜 인터페이스는 POSIX 에서 표준화하였다.- POSIX(Portable Operating System Interface): 유닉스 계열 운영체제 간 이식성을 높이기 위한 표준
이러한 인터페이스는 POSIX에서 사용자 공간 API의 형태로 표준화되었으며, 커널은 이를 기반으로 VFS를 통해 실제 파일 시스템 동작으로 연결한다.
설계 및 구현
Node.js에서는 표준 POSIX 함수를 이용하여 파일 시스템과 상호 작용을 할 수 있는 node:fs 모듈을 제공해준다.
해당 모듈을 실제 파일 시스템을 사용하기에, writeFile() 혹은 readFile() 등의 API를 호출하면 실제 파일을 저장하거나 저장된 파일을 읽어온다.
하지만, 간단하게 파일시스템을 구현하고 이에 대해 API를 제공하기 위해 실제 데이터를 저장하여 영속성을 보장하기 보단, 메모리에 저장하는 방식을 선택하여 설계하였다.
리눅스의 파일 시스템을 모방하여 실제 데이터를 생성, 조회, 삭제가 가능하고 폴더를 통해 계층 구조를 이룰 수 있도록 하는 것이 목표이다.
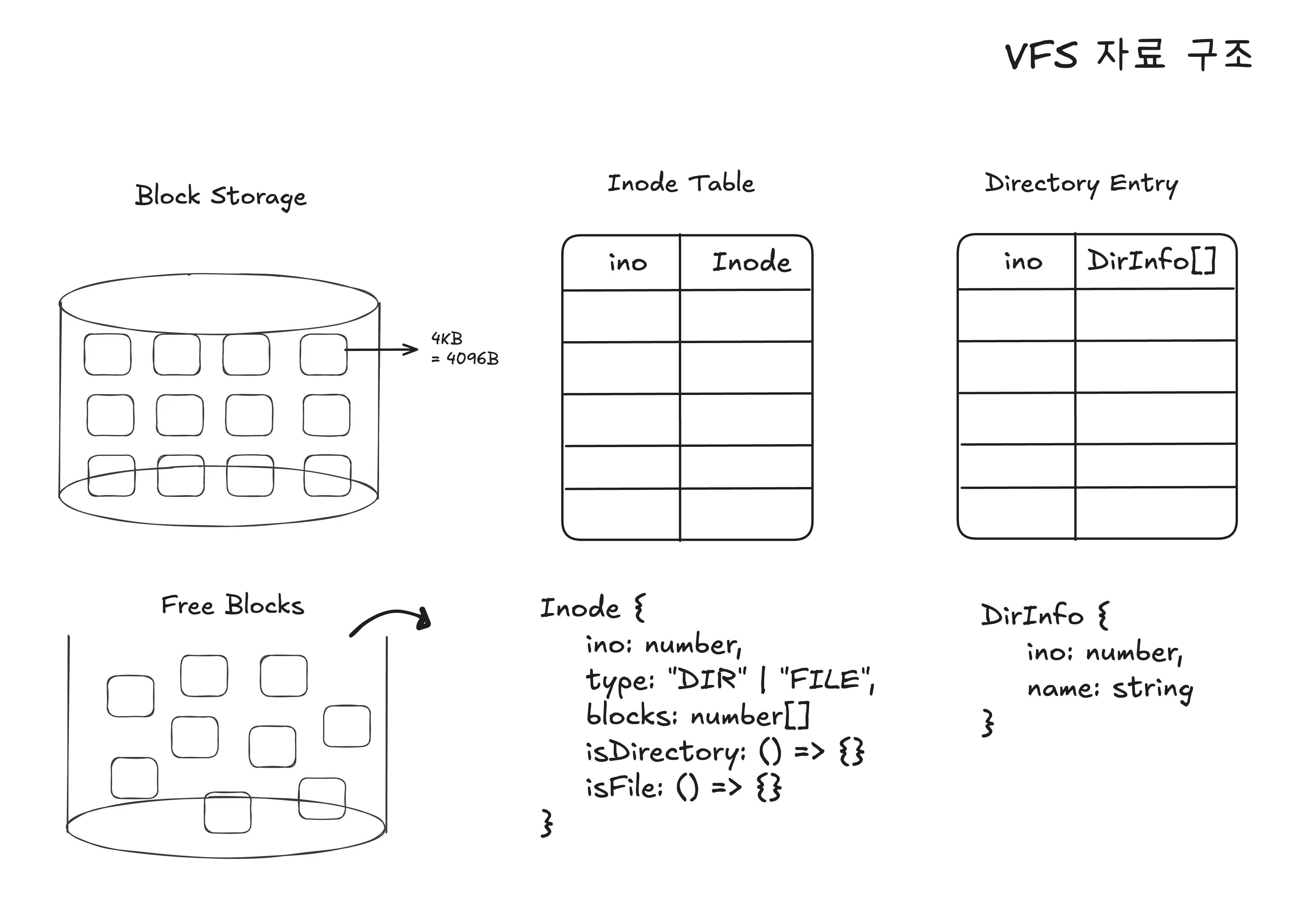
구현을 위해 필요한 자료구조는 다음과 같다.
blockStorage:파일의 실제 데이터 내용을 블록 단위로 저장하는 공간- 하나의 데이터 블록은 4KB 단위로 구분
freeBlocks: 삭제되거나 반납된 재사용 가능한 데이터 블록 저장소- 만약 해제된 블록이 존재한다면 해당 블록을 먼저 이용하여 파일 형성
directoryEntry: 디렉토리 내부에 존재하는 파일/폴더 목록 저장inodeTable: 파일/디렉터리의 inode(메타데이터) 저장 공간inode: 파일 또는 디렉토리의 메타데이터 저장 공간blocks[]하나의 파일을 형성하는 데이터 블록 인덱스 값의 배열
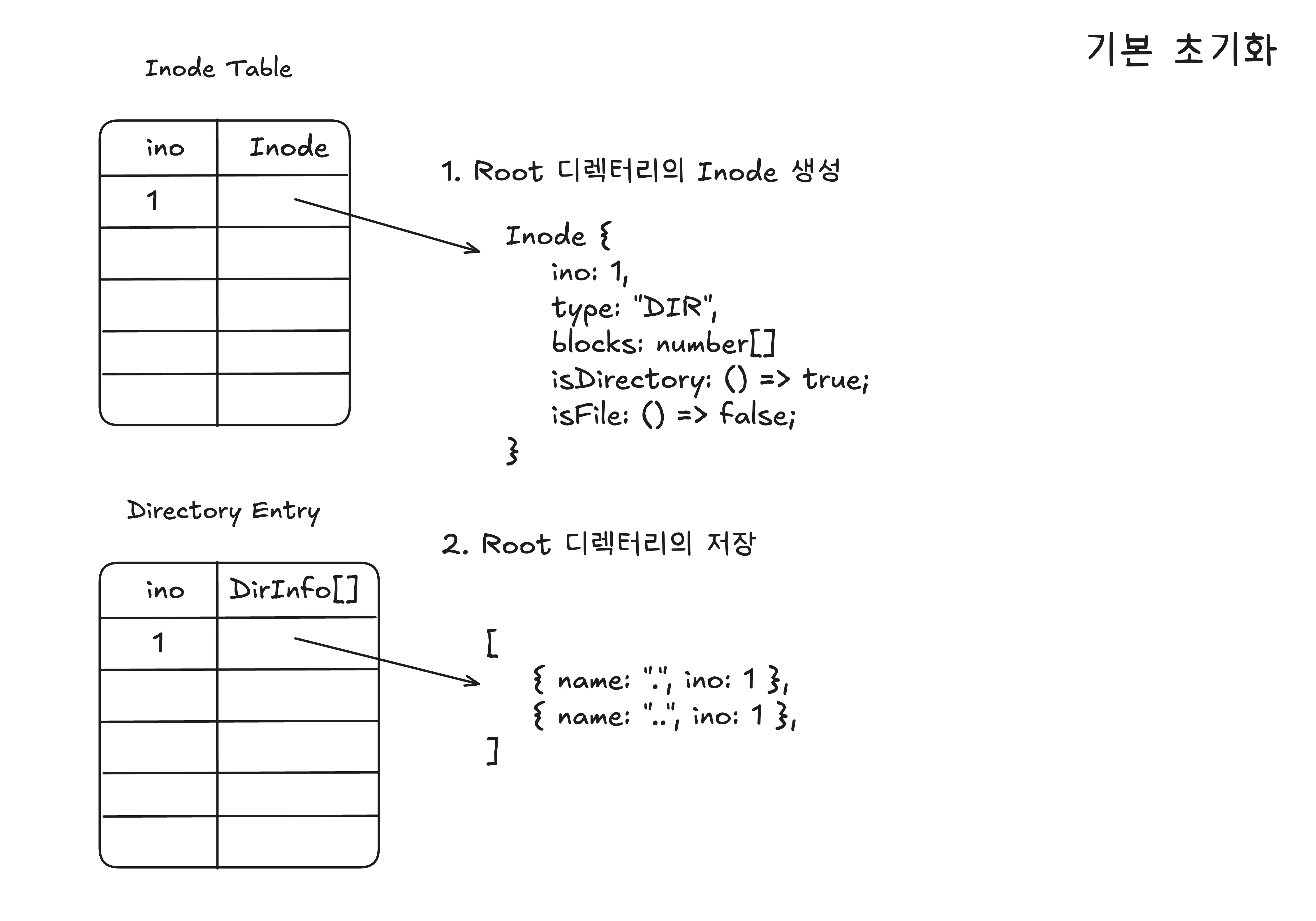
서버가 시작되면 파일 시스템을 기본적으로 초기화시켜줘야 한다.
파일을 저장하기 위해 Root 경로를 초기화 시켜주도록 하였다.
inode: 디렉터리는 저장할 데이터가 없기 때문에blocks는 빈 배열을 저장하면 1번의ino(inode number)를 갖는다.Directory Entry: Root 디렉터리는 현재 폴더, 이전 폴더 모두 자신을 가리켜야 하기 때문에.,..모두 자기 자신인 1번ino를 가리킨다.
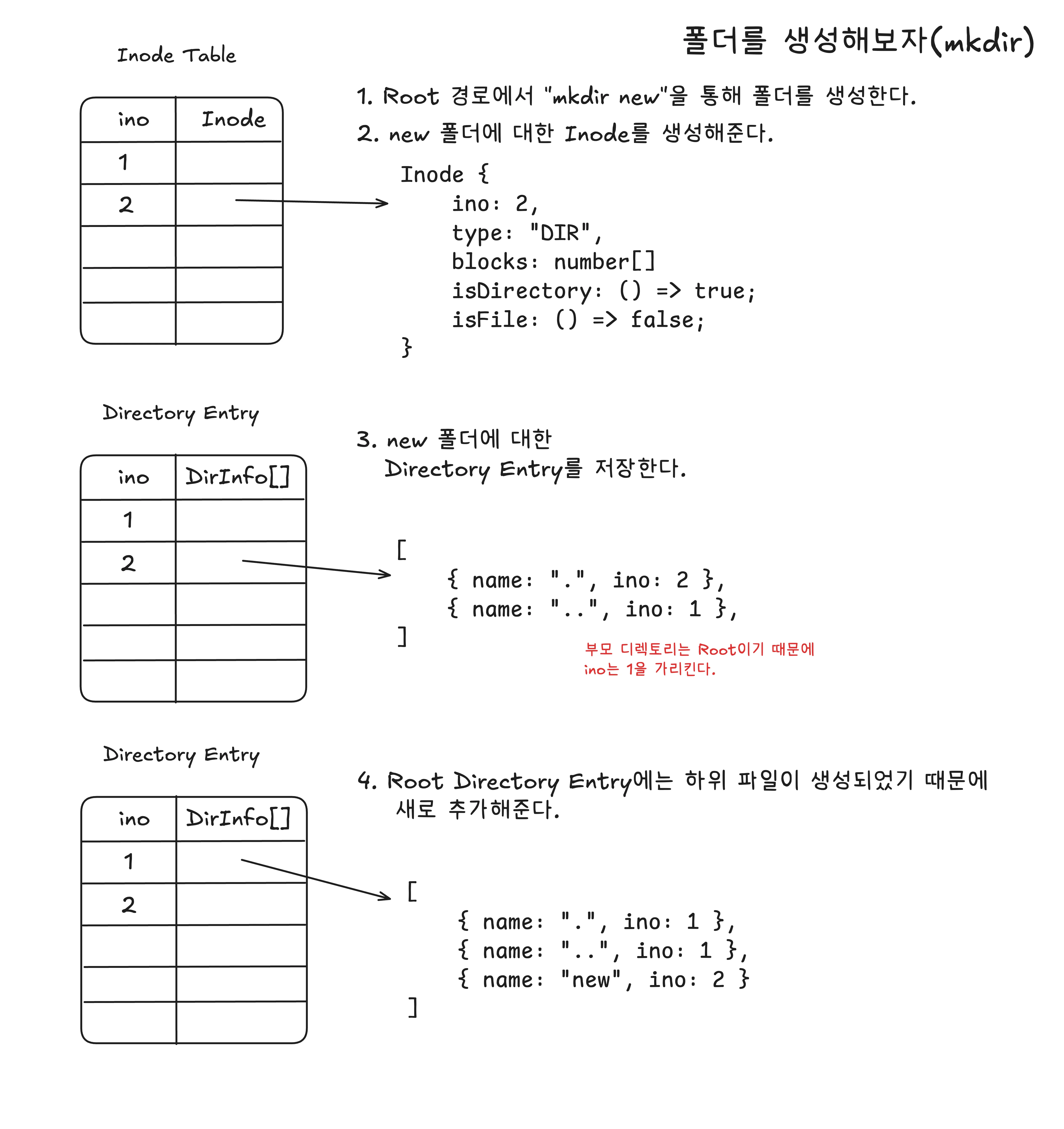
new라는 폴더를 만드는 과정이다.
inode: 마찬가지로 디렉터리는 데이터가 없기 때문에blocks는 빈 배열을 저장한다. 2번째로 생성된 데이터이기 때문에 2번ino를 갖는다.Directory Entry: 현재 폴더.는 자기 자신을 가리키며, 상위 폴더는 Root 폴더이기 때문에..는 1번ino를 갖는다.Root: 상위 폴더인Root폴더는 하위 폴더new가 생성되었기 때문에,new라는 폴더를 디렉터리 엔트리에 추가해준다.
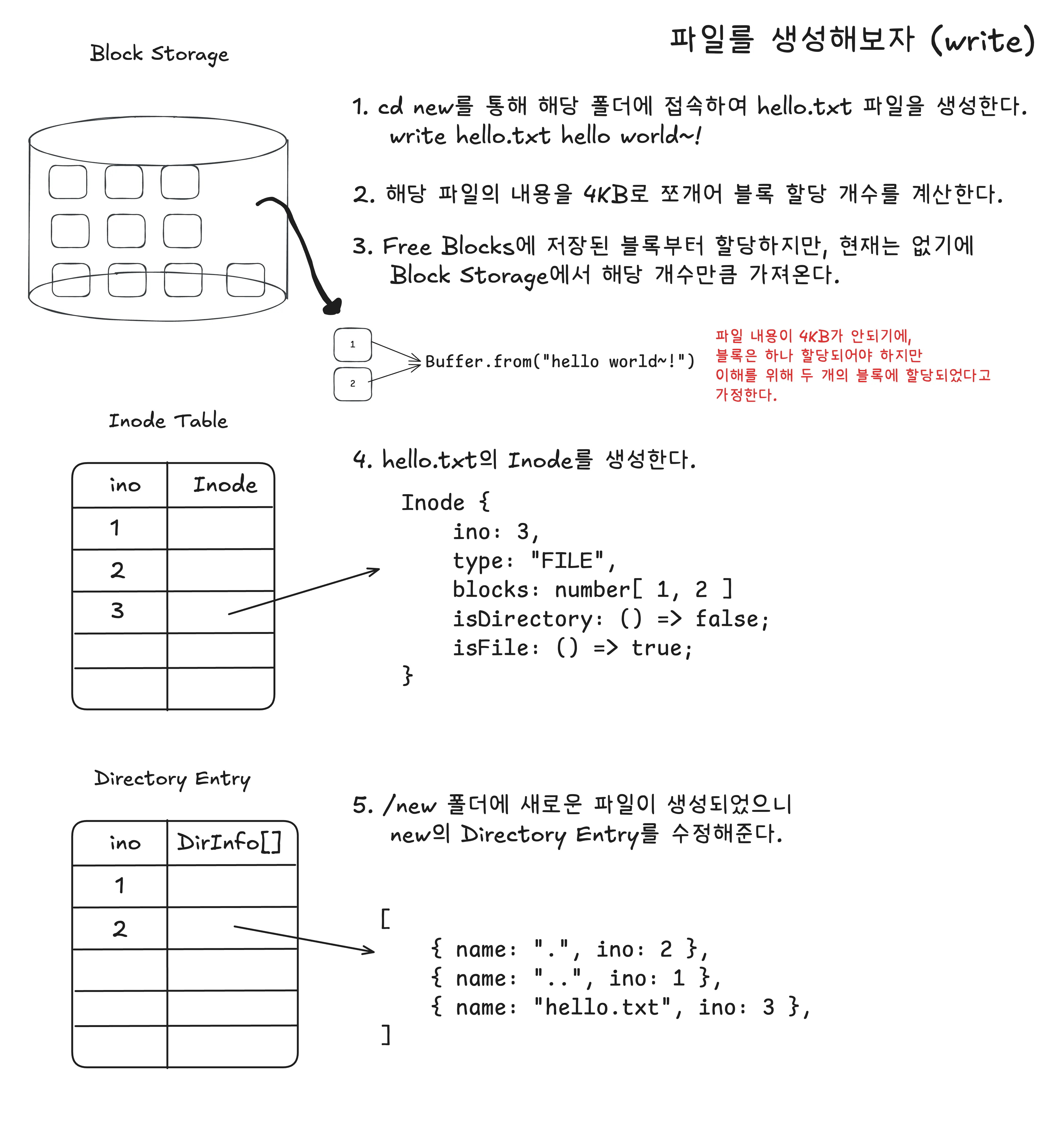
hello.txt라는 파일을 생성하는 과정이다.
block storage: 해당 파일이 갖는 파일 내용을 4KB로 나눠 사용할 데이터 블록의 개수를 계산하여 차례대로 데이터 블록에 할당한다.- 이 때 만약
free blocks자료구조에 남아있는 블록이 존재한다면 해당 블록을 먼저 사용한다.
- 이 때 만약
inode: 저장할 데이터는 파일 형식이기 때문에 할당한 데이터 블록의 인덱스 값을blocks에 담아준다.new: 현재new폴더 내부에 하나의 파일이 생성되었기 때문에hello.txt를 추가해준다.
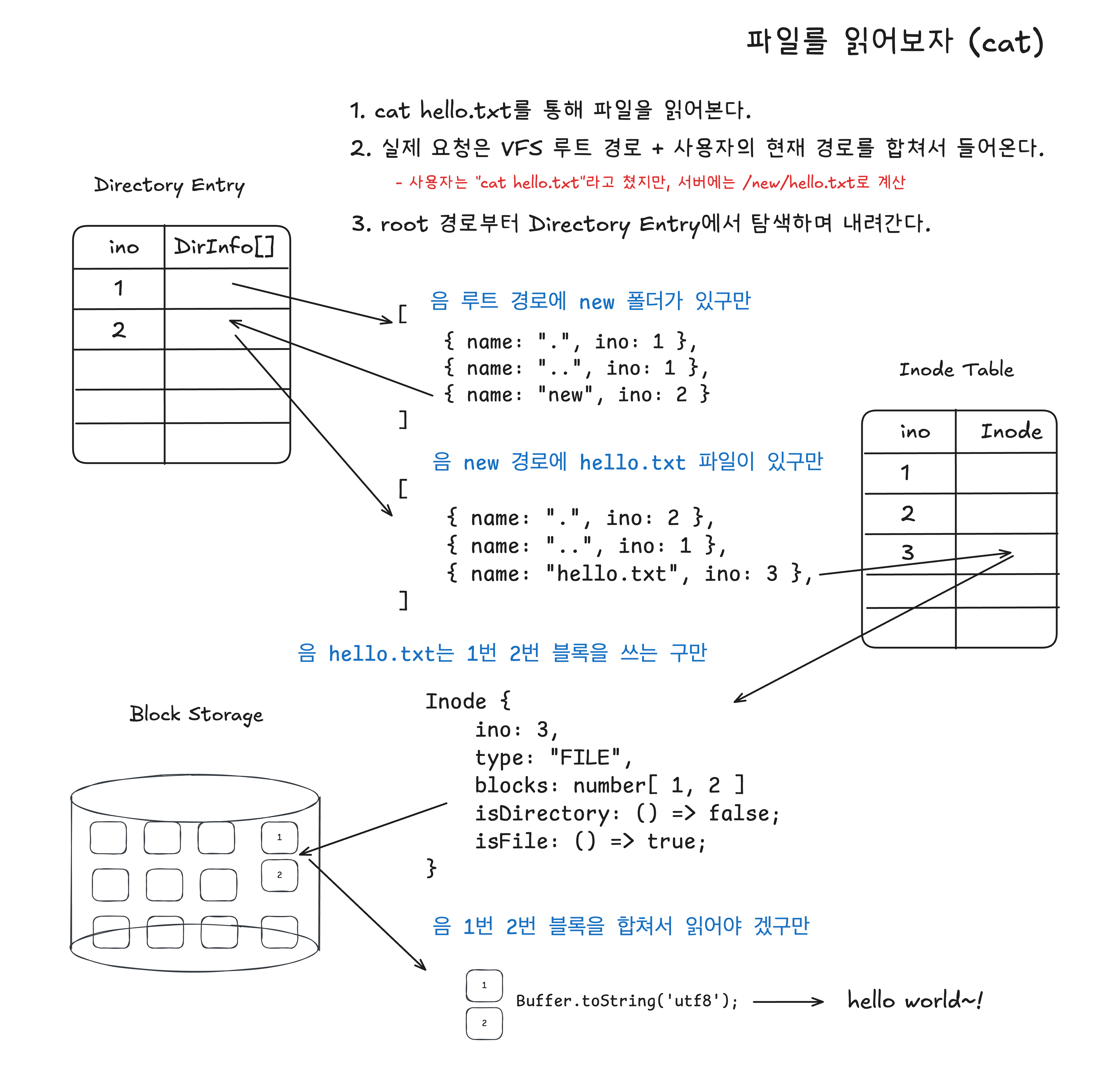
hello.txt라는 파일을 읽기위한 과정이다.
사용자가 입력한 경로에 대해 Root 경로부터 시작하여 해당 파일을 찾아간다.
Directory Entry에 1번 ino를 갖는 Root 폴더 내부에new폴더가 존재하는 지 확인한다.new폴더의 2번 ino에 저장된 Directory Entry를 가져와서hello.txt파일을 조회한다.hello.txt파일의 3번 ino를inode table에서 조회하여 inode 데이터를 조회한다.- inode 데이터가 갖는 blocks를
block storage에서 조회한다. - 조회한 데이터를 합쳐서 출력한다.
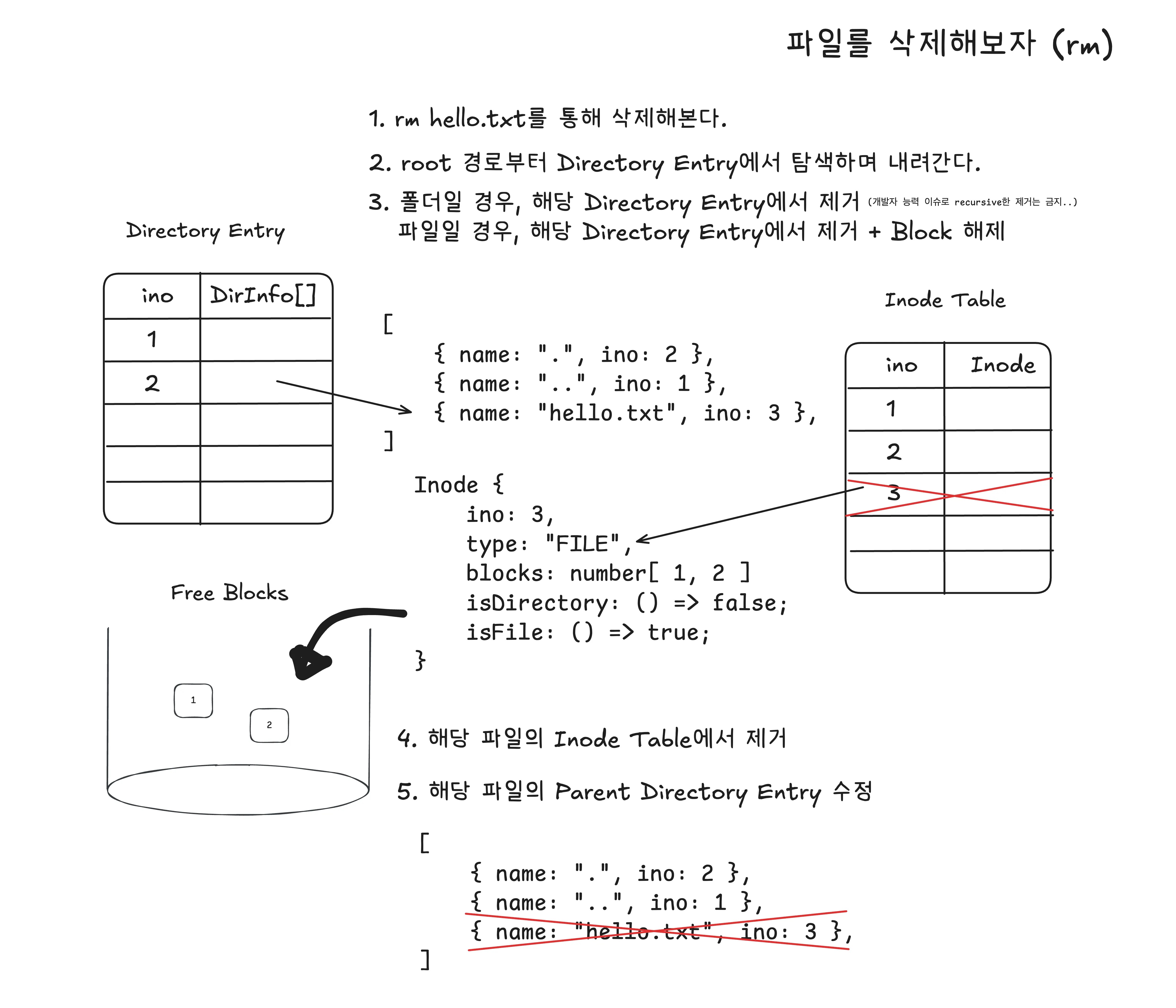
마지막으로 hello.txt 파일을 삭제하기 위한 과정이다.
해당 파일만 삭제하는 것이 아닌, 파일의 데이터를 저장하고 있는 테이블을 모두 정리해줘야 한다.
hello.txt가 갖고 있는 데이터 블록을 모두 해제해준다.- 할당 해제된 블록들은 모두
free blocks로 저장해준다.
- 할당 해제된 블록들은 모두
inode table에서hello.txt에 대한 정보를 제거해준다.hello.txt를 갖는new폴더의 Directory Entry에서도 정보를 제거해준다.
이 때, rm -rf와 같은 명령어는 하위 디렉토리와 파일이 존재하더라도 모두 제거할 수 있는데, 이에 대해서는 해당 rm 메서드를 재귀적으로 호출하여 제거해주어야 한다. (개발자 능력 이슈로 일단 해당 기능은 구현을 못함 😅 )
전체 다이어그램은 여기서 확인이 가능하다.