Redis의 Sorted Set으로 랭킹 시스템 만들어보기


개요
레디스는 신이야
부스트캠프를 하는 동료와 항상 장난스럽게 주고 받는 말이다. Redis에서 제공하는 다양한 자료구조와 기능들 덕분에 데이터 저장소, 캐싱, 메세지 큐 등으로 다양하게 활용할 수 있어, 어떤 문제만 발생하면 모두 레디스로 해결할 수 있다는 이야기를 장난스럽게 주고 받곤 하였다.
Redis에 대해서는 자주 들어 익히 알고는 있었지만 어떤 장단점을 갖고 있으며 어떤 특징들을 통해 다양한 기능들을 제공할 수 있는 지에 대해서는 알고 있지 않았기 때문에, 이번 기회에 Redis를 학습해보며 간단한 프로젝트를 통해 몸소 Redis를 체감해보려 하였다.
간단한 Redis
Redis 공식문서에서 언급하는 주요한 특징들만 정리를 해보려고 한다.
In-Memory Data StoreOn-Dist PersistenceBuilt-In ReplicationData Types
In-Memory Data Store
레디스는 다른 데이터베이스처럼 데이터를 물리적인 저장소(디스크 등)에 저장하는 것이 아닌, 메모리에 저장하고 관리한다.
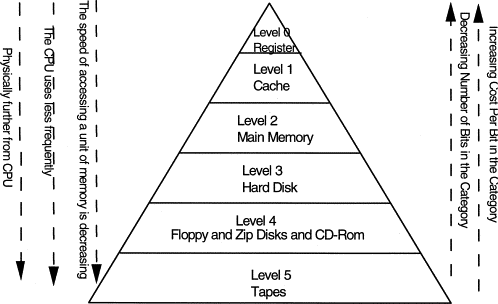
이미지에서 보이는 것과 같이 아래로 내려갈수록 더 많은 데이터를 저장할 수 있는 대신 데이터를 조회할 수 있는 속도가 느려지는데, 그에 비해 상단으로 갈수록 데이터를 조회할 수 있는 속도가 압도적으로 빨라진다.
이러한 특성으로 인해 자주 조회가 이루어지는 데이터를 DB에서 요청하는 것이 아닌 레디스에 미리 데이터를 저장해두고 더욱 빠르게 클라이언트로 원하는 데이터를 반환해주는 캐싱 전략을 위해 레디스를 많이 활용한다.
On-Dist Persistence
메모리에 데이터를 저장한다는 의미는 서버가 종료된다면 저장된 데이터가 모두 휘발된다는 의미다. 즉, 예상치 못한 종료로 인해 레디스 서버가 터져버린다면 내부적으로 저장되고 있던 데이터가 모두 유실될 위험이 존재한다.
이러한 잠재적 위험에 대해 레디스는 여러 전략을 통해 데이터의 영속성을 보장해준다.
RDB: 주기적으로 메모리에 저장된 모든 데이터를dump.rdb라는 스냅샷 파일로 저장한다.- 하나의 단일 파일로 관리되며 파일 크기가 작고 빠르게 복구가 가능하다.
- 주기 별로 버전 관리가 가능하다.
- 마지막 스냅샷 이후의 데이터가 유실될 가능성이 존재하다.
AOF: 모든 '쓰기' 명령어를 기록하고 서버가 시작되면 해당 로그를 통해 모든 데이터를 명령어를 통해 복원한다.fsync정책을 통해 데이터 손실을 최소화할 수 있다.fsync every query: 모든 명령어마다 디스크에 기록fsync everysec: 기본값이며 1초마다 기록fsync no: 기록하지 않음
- 파일이 너무 커지면 자동적으로 최소 명령어 집합으로 압축
- 모든 명령어를 저장하기 때문에 파일의 크기가 크며 복구 속도가 느리다.
RDB + AOF: 두 개의 방식을 조합할 수 있다.No Persistence: 영속성을 부여하지 않으며 주로 캐싱할 때 사용할 수 있다.
메모리에 저장된 데이터를 디스크로 옮기는 과정은 어떤 방식을 선택하든 백그라운드에서의 리소스 소모가 필요하기 때문에 레디스 사용 전략에 따라, 환경에 따라 영속성을 부여할 것인지, 어떤 전략을 선택할 것인지 trade-off를 따져가며 선택해볼 수 있을 것 같다.
Built-In Replication
Master-Replica 구조로 데이터의 고가용성(High-Availability)와 데이터 안전성을 보장한다.
- Master와 Replica 인스턴스들은 항상 연결되어 있으며 Master에 쓰여진 데이터는 Replica에 복제된다.
- Master와 Replica의 연결이 끊어지면 Replica는 재연결을 시도하며 연결이 끊어진 동안의 데이터에 대해서만 재동기화(Partial-Resynchronization)를 실행한다.
- 만약 부분적 재동기화에 실패한다면 Replica는 전체 재동기화(Full Resynchronization)를 시도한다.
Data Types
레디스는 key-value database이며 다양한 데이터를 저장할 수 있는 여러 자료구조를 제공한다.

| 데이터 타입 | 설명 및 특징 | 주요 사용 사례 (Use Cases) |
|---|---|---|
| String | 가장 기본적인 타입. 텍스트, 정수, 바이너리 데이터(이미지 등)를 최대 512MB까지 저장 가능. | 캐싱, 세션 저장, 카운터(좋아요 수), 비트맵 기반 데이터 |
| List | 순서가 유지되는 문자열 목록(Linked List). 양쪽 끝에서의 추가/삭제가 매우 빠름(O(1)). | 메시지 큐, 최근 게시물 목록, 타임라인 |
| Hash | Field-Value 쌍으로 이루어진 컬렉션. 객체(Object) 데이터를 저장하기에 최적화됨. | 사용자 프로필, 장바구니, 설정 정보 |
| Set | 순서가 없고 중복을 허용하지 않는 문자열 집합. 교집합, 합집합, 차집합 연산 지원. | 태그 클라우드, 친구 목록, 유니크 방문자 추적, 블랙리스트 |
| Sorted Set (ZSet) | Set과 유사하지만 각 멤버가 Score(점수)를 가짐. Score를 기준으로 항상 정렬된 상태 유지. | 실시간 랭킹(Leaderboard), 우선순위 큐, 시계열 데이터(Score=타임스탬프) |
| Stream | 로그 데이터와 같이 계속 추가되는 데이터 처리를 위한 자료구조. 소비자 그룹(Consumer Group) 기능 지원. | 이벤트 소싱, 실시간 로그 수집, 채팅 히스토리, 센서 데이터 수집 |
| Bitmap | String 데이터의 비트(bit) 하나하나를 제어하는 방식. 메모리를 매우 효율적으로 사용. | 일일 사용자 출석 체크, 사용자 접속 여부(On/Off), 기능 플래그 |
| Bitfield | 문자열 하나에 여러 개의 작은 정수 필드를 비트 단위로 저장하고 조작. | 게임 플레이어의 상태 정보, 작은 카운터 집합 |
| Geospatial | 위도/경도 좌표를 저장하고 거리 계산 및 반경 검색을 지원하는 인덱스. (내부적으로 Sorted Set 사용) | 주변 매장 찾기, 배달원 위치 추적, 지오펜싱(Geo-fencing) |
| JSON | 계층적 구조를 가진 JSON 문서를 네이티브로 저장, 조회, 수정 가능. (Redis Stack 기능) | 복잡한 객체 저장, 부분 업데이트가 필요한 문서 데이터, 카탈로그 |
| Probabilistic | HyperLogLog, Bloom Filter 등 확률적 알고리즘을 사용하여 적은 메모리로 근사치를 계산. | 대규모 유니크 카운트(UV), 아이템 존재 여부 필터링(Bloom Filter) |
| Time Series | 시간과 값의 쌍을 효율적으로 저장하고 집계 쿼리(평균, 합계 등)를 수행. (Redis Stack 기능) | IoT 센서 모니터링, 주식 가격 추적, 시스템 메트릭 수집 |
| Vector | 고차원 벡터 데이터를 저장하고 유사도 검색(Vector Similarity Search)을 지원. | AI 추천 시스템, 이미지/텍스트 유사도 검색, 시맨틱 검색 |
Sorted Set
설명
레디스를 학습하다가 Sorted Set이라는 자료구조에 매료되어 더 깊이 학습을 진행하게 되었다.
Sorted Set이란 score이란 데이터와 연결된 고유한 문자열 컬렉션을 의미한다.
해당 자료구조는 Set과 Hash이 합쳐진 느낌을 갖는데, 값의 유일성을 보장하면서 key-value 형태의 구조를 갖고 있기 때문이다. 하지만 Set 자료구조는 스스로 정렬하지 않기 때문에, Sorted Set의 각 Member(원소)는 부동소수점으로 표현될 수 있는 Score와 연결되어 있다.
const res1 = await client.zAdd('racer_scores', { score: 10, value: 'Norem' }); console.log(res1); // >>> 1const res2 = await client.zAdd('racer_scores', { score: 12, value: 'Castilla' }); console.log(res2); // >>> 1
const res3 = await client.zAdd('racer_scores', [ { score: 8, value: 'Sam-Bodden' }, { score: 10, value: 'Royce' }, { score: 6, value: 'Ford' }, { score: 14, value: 'Prickett' }, { score: 12, value: 'Castilla' } ]); console.log(res3); // >>> 4
레디스
ZADD명령어는 Sorted Set 자료구조에 요소를 추가한다.
Sorted Set은 데이터가 정렬될 때 두 가지 정렬 규칙에 의해 저장된다.
- B와 A가 있을 때, A의 스코어가 B의 스코어보다 더 크다면 A가 B보다 더 크다.
- B와 A가 동일한 스코어를 가질 때, A 문자열의 사전 순서가 B보다 크다면 A가 B보다 크다.
위 코드와 같이 요소를 추가하면 추가된 요소의 개수를 반환하며 아래와 같이 보여질 수 있다.
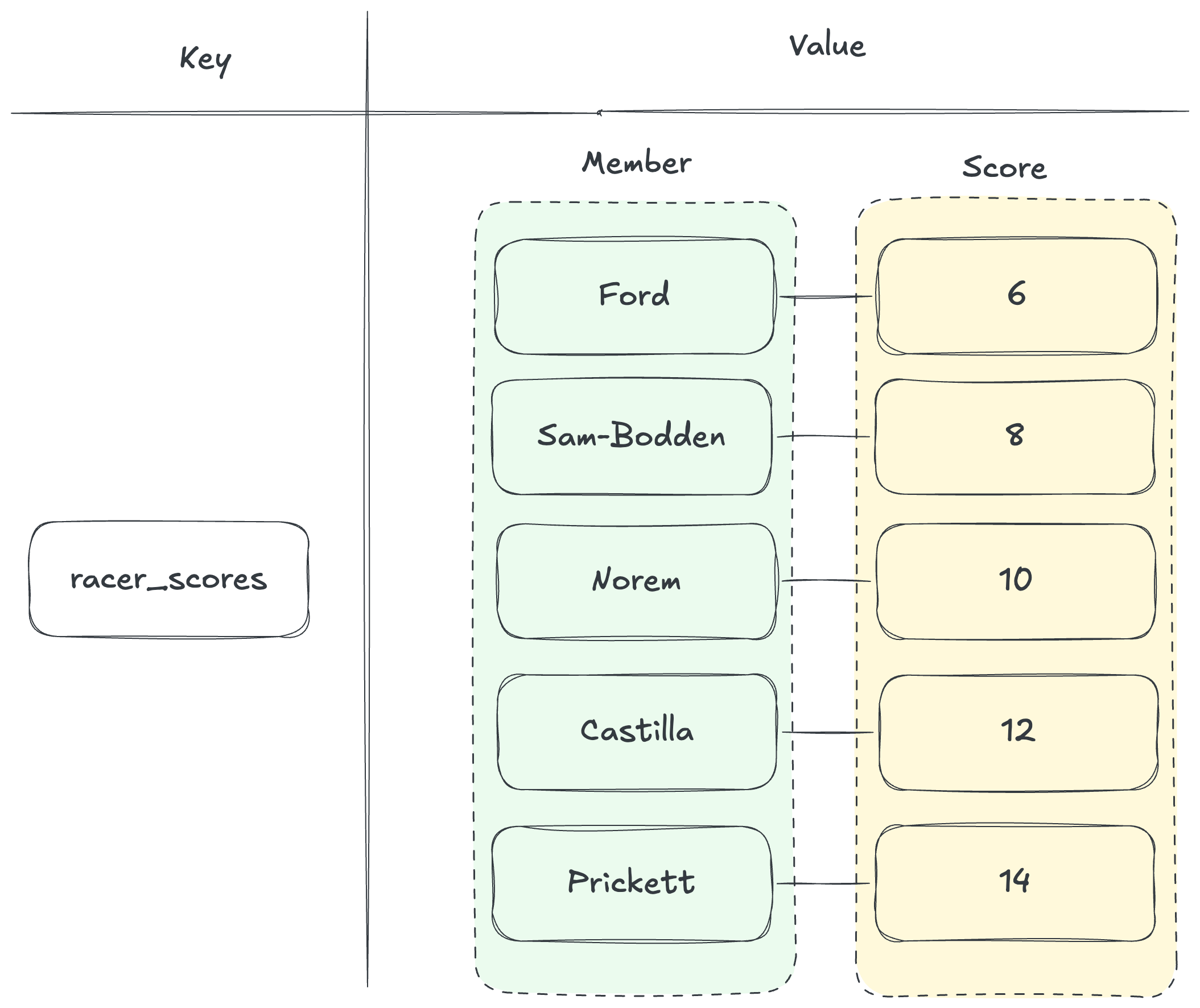
WITHSCORE 명령어와 함께 ZRANGE로 데이터를 조회하면 다음과 같이 score로 정렬된 데이터가 나오는 것을 확인해볼 수 있다.
- 첫 인덱스(0)에서 마지막 인덱스(-1)까지 조회
const res6 = await client.zRangeWithScores('racer_scores', 0, -1);
console.log(res6);
// >>> [
// { value: 'Ford', score: 6 }, { value: 'Sam-Bodden', score: 8 },
// { value: 'Norem', score: 10 }, { value: 'Royce', score: 10 },
// { value: 'Castilla', score: 12 }, { value: 'Prickett', score: 14 }
// ]성능
Sorted Set의 삽입, 삭제, 조회를 포함한 대부분의 연산은 ** O(log(n))** 의 시간 복잡도를 갖고 있으며, ZRANGE와 같이 범위를 통해 조회를 할 땐 반환할 범위 m을 포함한 O(log(n) + m)의 시간 복잡도가 발생한다.
데이터가 많아질수록 삽입과 삭제에 대한 시간 복잡도가 늘어날 법도 한데, 내부적으로 어떻게 동작되길래 일정한 시간 복잡도를 유지할 수 있을 지가 궁금해졌다.
스킵 리스트
스킵 리스트는 이진 트리를 대신할 수 있는 자료 구조로, 이진 트리와 같이 강제로 트리의 균형을 잡아가기 보단 확률론적인 균형을 통해 데이터를 정렬하며 삽입, 삭제에 대해 더 간단하고 더 빠른 성능을 보인다.
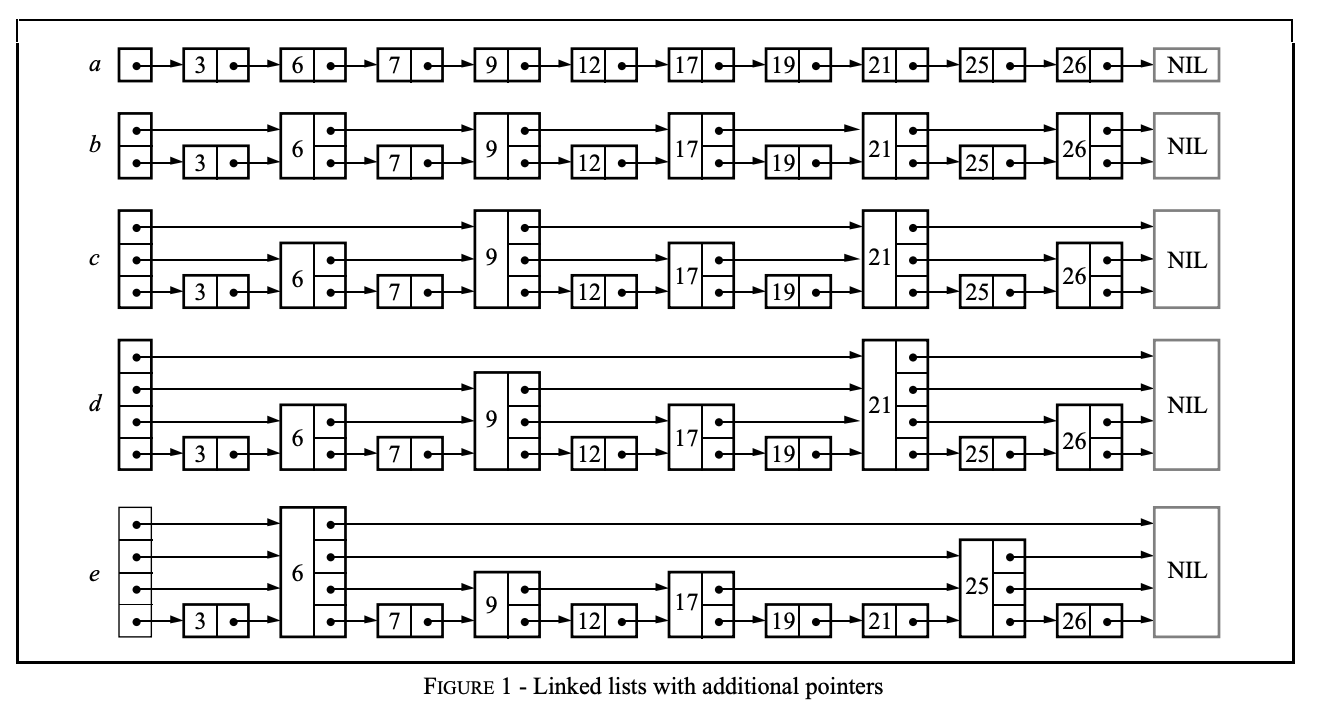
위 이미지에서는 a~e 까지의 리스트를 보여준다.
기본적으로 a는 다음 노드의 포인터를 갖는 연결 리스트이며 데이터 조회를 위해서는 순차적으로 노드를 검색해야 하기 때문에 O(n)의 시간 복잡도를 갖는다.
하지만 만약 건너 뛸 수 있는 포인터를 추가한다면 조회의 성능은 더 빨라질 수 있을 것이다. 예를 들어, b 리스트와 같이 2개의 노드마다 포인터를 가리키는 리스트를 하나 더 추가하면 최대 [n/2] + 1의 노드만 검사하면 조회가 가능할 것이다.
즉, 2^i 의 간격으로 포인트를 갖는 리스트가 추가될수록 조회에 대한 시간복잡도는 O(log n)의 시간으로 수렴하게 된다.
하지만 이러한 방식은 조회의 성능은 높여주지만 삽입과 삭제에 대해 유연하지 못하다는 단점이 존재한다. 노드가 추가된다면 해당 노드에 맞춰 다시 모든 리스트의 포인터를 계산해줘야 하기 때문이다.
이런 문제에 대해서 확률적으로 노드의 레벨을 결정하여 포인터를 생성해주게 된다.
e 리스트를 확인해보면 각 노드들은 랜덤한 레벨을 가지며 이를 통해 포인터를 형성하고 있다. 이렇게 각 노드들이 확률적으로 랜덤한 레벨을 갖게 된다면 중간 노드가 삽입되거나 삭제되더라도, 해당 노드의 앞 뒤 노드 포인터만 수정해주면 되기 때문에 기존 문제를 개선시킬 수 있다.
레디스 스킵 리스트
레디스에서는 기존의 스킵 리스트를 수정하여 사용하고 있다.
#define ZSKIPLIST_MAXLEVEL 32 /* Should be enough for 2^64 elements */
#define ZSKIPLIST_P 0.25 /* Skiplist P = 1/4 */Redis 소스코드를 확인해보면 스킵 리스트에 대한 설정 값을 확인해볼 수 있다.
- 레디스 스킵 리스트의 최대 레벨은 32이다.
- 레디스 스킵 리스트의 새로운 레벨 생성 확률을 25%이다.
/* ZSETs use a specialized version of Skiplists */ typedef struct zskiplistNode { sds ele; double score; struct zskiplistNode *backward; struct zskiplistLevel { struct zskiplistNode *forward; unsigned long span; } level[]; } zskiplistNode;
typedef struct zskiplist { struct zskiplistNode *header, *tail; unsigned long length; int level; size_t alloc_size; } zskiplist;
zskiplistNode에서는 이전 노드를 가리키는 backward 포인터를 저장하며 각 레벨마다 다음 노드를 가리키는 forward 포인터와 그리고 다음 노드까지의 개수를 저장하는 span으로 구성되어 있다.
그리고 스킵 리스트를 구성하는 zskiplist는 zskiplistNode 형태의 header와 tail을 통해 리스트를 관리한다.
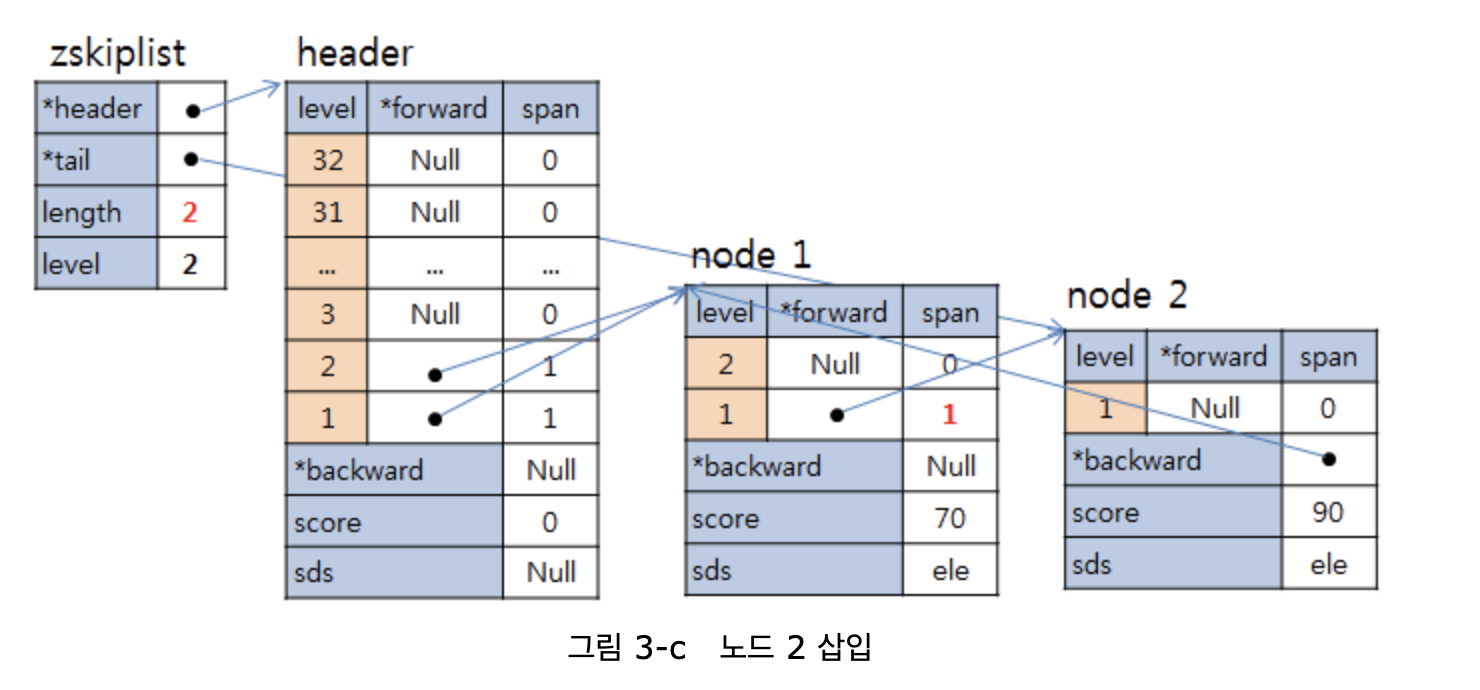
각각 score가 70, 90인 노드가 추가된다면 다음과 같이 Skip List에 데이터가 저장된다.
이렇게 정렬된 데이터를 저장하기 위해 Skip List 자료 구조를 활용하여 대부분의 연산에서 일정한 시간 복잡도 (O(log n))을 유지하기 때문에 다음과 같은 결과를 보여줄 수 있다.
def zaddinc(conn,key,start_index,end_index):
i = start_index
while i <= end_index:
conn.zadd(key, 'val-'+str(i), i)
i = i+1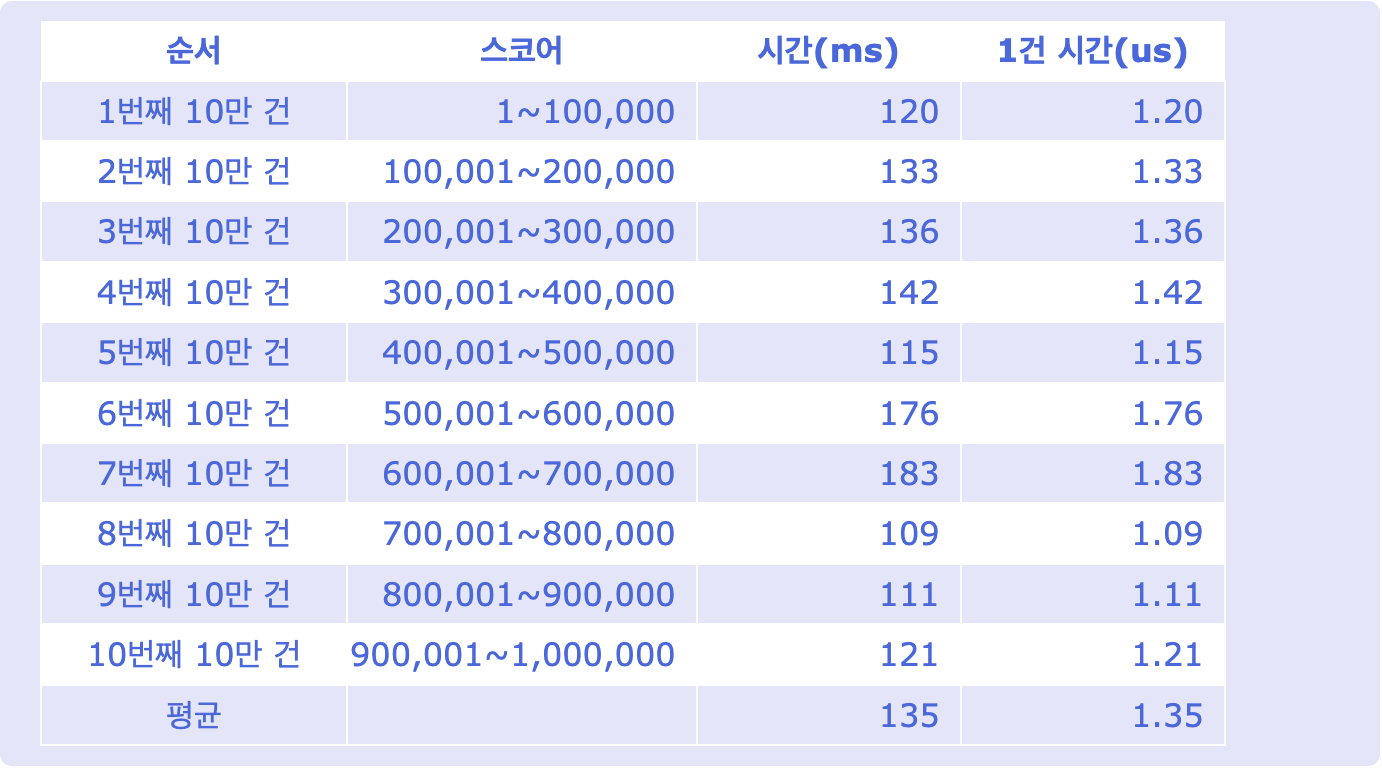
기획
1. 프로젝트 주제
Sorted set 자료구조를 통해 간단한 랭킹 시스템을 구현해봄으로써 레디스를 직접 연동해봄과 동시에 해당 자료구조를 활용해보는 경험을 가져가보려 하였다.
랭킹 시스템이 존재하기 위해서는 무엇을 순위로 매길 지를 결정하여야 했고 간단하게 즐길 수 있는 게임을 함께 개발하여 게임 점수를 통해 사용자 간의 순위를 매길 수 있도록 기획하였다.
간단하게 어떤 게임을 생성할 수 있을 지 GPT를 통해 리스트를 받았는데,
1️⃣ 10초 클릭 챌린지 (가장 추천) 2️⃣ 반응속도 게임 (Skill 기반) 3️⃣ 매일 퀴즈 랭킹 (누적형) 4️⃣ 리스크 선택 게임 (운빨 + 전략)
막 구미가 땡기는 게임은 별로 존재하지 않았다. 사실 개인적으로 JS를 통해 테트리스 같은 게임을 만들어서 사용자의 Score를 측정하는 프로젝트를 해보고 싶었으나, 그렇게 되면 프로젝트의 목적이 Redis에서 테트리스 구현으로 전도될 것 같다고 판단하였다.
아무래도 랭킹 시스템 구현을 최우선으로 생각하였기 때문에, 게임은 별로 재미가 없더라고 최대한 빠르게 구현해볼 수 있는 것으로 선택하였고 1️⃣ 10초 클릭 챌린지을 선택하게 되었다.
2. 랭킹 시스템
- 랭킹은 매일 매일 갱신된다.
- 하루의 랭킹에는 10순위까지 저장된다.
- 동일한 점수일 경우에는 최신순으로 정렬된다.
3. 회원 관리
- 사용자를 식별할 수 있는 무언가가 필요하다.
- 회원가입 및 로그인 시스템은 존재하지 않는다.
- 해당 회원 식별자를 통해 랭킹에 점수를 표시한다.
4. 개발
- 무료 Redis Cloud를 통해 데이터를 저장하고 있기 때문에 제공되는 용량과 커넥션을 초과하면 안된다.
- 무료 Redis Cloud는 30 Connection, 30 RAM 제공
설계 및 개발
FE
FE는 lovable을 통해 빠르게 생성하고 세부적인 요소들은 개발을 진행하면서 수정해나갔다.
식별자
FE에서는 랭킹 시스템에 필요한 회원 정보를 설계할 필요가 있었는데, 회원 가입과 로그인 기능을 구현하지 않고 회원을 구분지어야 했다.
로그인 기능 없이 클라이언트를 식별하기 위해 IP를 통해 구별하거나 회원마다 임의의 식별자를 붙여 구별할 수 있다고 생각했다.
IP를 식별자로 사용하기 위해서 다음과 같은 내용을 고려하였고
- 서버에서 클라이언트의 IP를 식별하여 반환해준다.
- 사용자가 쉽게 정보를 변경하기 어렵다.
- 사용자의 식별자에 의미를 부여하기 어렵다(못생겼다).
임의의 식별자를 사용하기 위해서는 다음과 같은 내용을 고려하였다.
- 사용자 식별자에 의미를 부여할 수 있다.
- 빠르게 구현이 가능하다.
- 중복될 가능성을 제거해야 한다.
- 사용자가 쉽게 정보를 변경할 수 있다.
사용자 정보 저장
빠르고 가볍게 프로젝트를 구현하는 것이 최우선 목표였기 때문에 후자를 선택하여 사용자가 자신만의 식별자를 생성하도록 기획하였다. 기본적으로 사용자가 생성한 자신의 정보는 local storage에 저장하였다.
사용자는 게임을 시작하기 전, 사용하고 싶은 닉네임을 입력한다.
- 해당 닉네임은 중복될 수 없다.
- 00시가 지나면 생성된 닉네임 리스트는 초기화된다. (00시 이후 동일 닉네임 생성 가능)
게임에 진입하였을 때, local storage 에 사용자 정보가 존재한다면 해당 세션을 유지한다.
랭킹 시스템은 일 단위로 초기화되기 때문에, 생성된 닉네임 또한 이에 맞춰 하루마다 초기화되어 다시 생성이 가능하도록 기능을 기획하였다. 물론 하루 이내에 이미 생성된 닉네임으로 재생성을 시도할 경우에는 중복으로 간주되어 요청이 거부된다.
그렇게 생성된 닉네임은 local storage에 저장하여 사용자 정보를 관리해주었는데, 가장 간단하게 저장하고 관리하기 쉽기 때문이다. 하지만 그만큼 사용자 또한 자신의 정보를 변경할 수 있다는 위험이 존재한다.
가장 큰 잠재적 위험으로는 사용자가 자신의 닉네임을 변경하여 게임을 진행할 경우 변경된 닉네임으로 랭킹 시스템에 개입될 수 있다고 판단하였다. 이러한 점에 대해서 서버에서 유효성 검사를 통해 차단할 수 있겠지만 "자신의 최고점을 갱신하는 서비스에서 굳이 다른 닉네임을 통해 점수를 여러 계정에 분산(?)시키는 이유가 있나?" 생각이 들어서 따로 막아두진 않았다.
BE
자료 구조
Redis에 저장할 데이터는 총 2개로 설계하였다.
1. 일일 닉네임 생성 리스트
사용자가 게임을 진행하기 위해서는 닉네임을 입력하여 자신의 정보를 생성하고 입장해야 한다. 이 때 닉네임 중복 검사를 진행해야 하는데 닉네임 중복을 검사를 위해 이미 생성된 닉네임 정보를 서버에서 알고 있어야 한다.
이를 위해 레디스에서 제공하는 Set 자료구조를 이용하여 하루에 생성된 닉네임 리스트를 저장하도록 설계하였다.
닉네임 리스트는 하루 단위로 데이터를 저장해야하기 때문에, key 값으로는 해당 일자에 대한 Timestamp를 포함하여 nicknames:YYYY-MM-DD와 같은 형태를 갖도록 하였다.
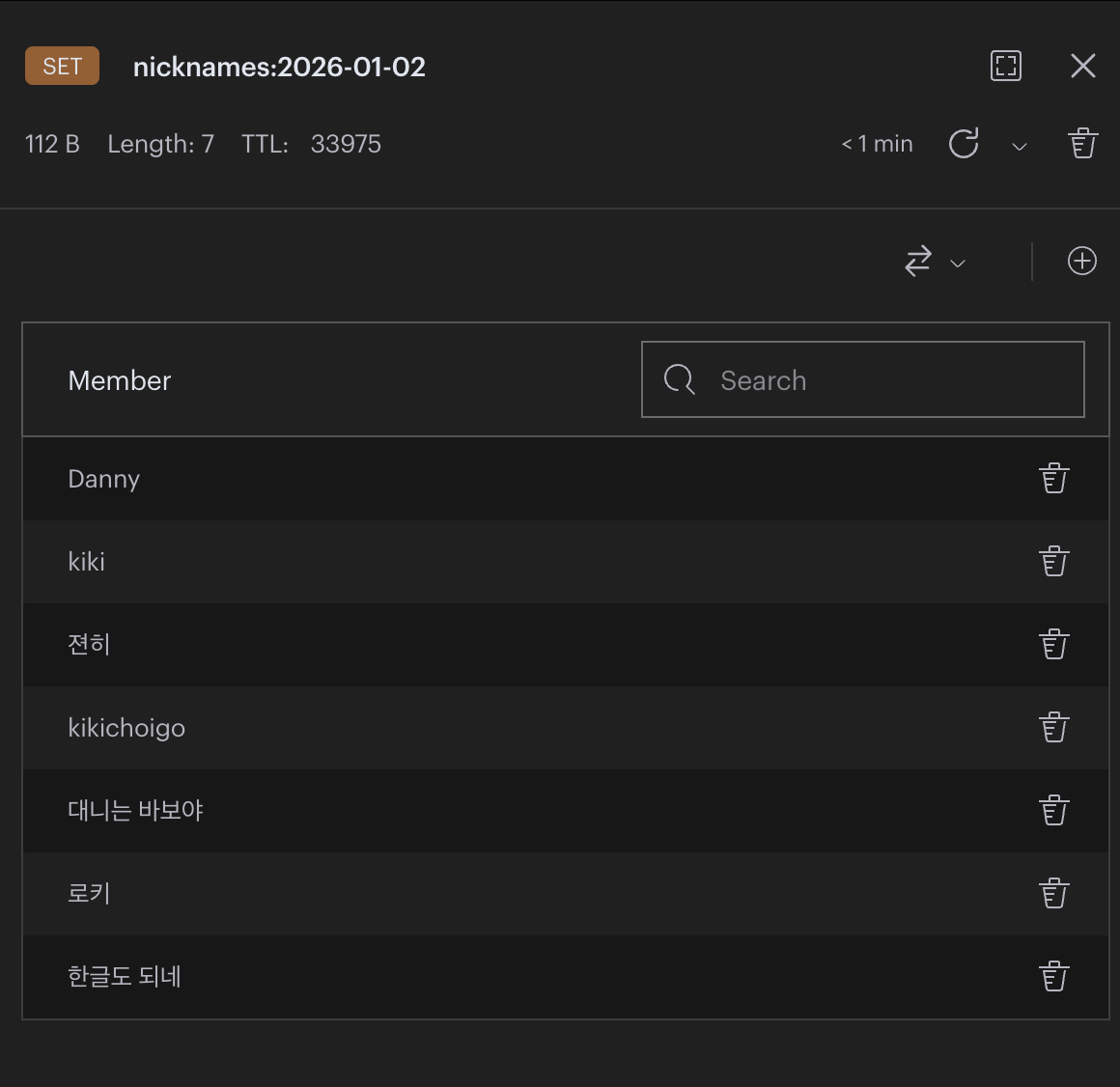
추가적으로, 무료 Redis Cloud 용량은 30MB 제한이 있기 때문에 일일 닉네임 리스트와 같이 축적되는 데이터를 관리해줄 필요가 존재하였다. 닉네임 리스트는 단순히 닉네임 중복 검사를 위해서만 필요하였기 때문에 해당 자료구조에 TTL(Time To Live)를 설정하여, 00시를 넘어가면 자동으로 제거되도록 설정해주었다.
2. 일일 랭킹 시스템
랭킹 시스템은 sorted set을 활용하여 데이터를 저장하였는데, 해당 자료구조 또한 일마다 새로운 랭킹 시스템 데이터를 생성해야하기 때문에 key 값에는 timestamp 를 추가한 ranking:YYYY-MM-DD와 같은 형태를 갖도록 설계하였다.
value 값으로는 member와 score를 구분하여 설계할 필요가 있었다. 랭킹 시스템에 저장될 데이터는 다음과 같다.
nickname: 사용자 식별자difference: 타이머 오차
만약 nickname:difference와 같은 방식으로 데이터를 저장한다면 Sorted Set에 적절하게 삽입이 가능하다. 예를 들어, 데이터를 다음과 같이 저장한다면
member: Danny
score: 1"Danny라는 닉네임을 가진 유저가 11초를 기록하였다"라는 의미를 갖게 된다.
하지만 이와 같이 저장하면 두 가지 문제가 발생한다.
Danny가 게임을 한 판 더 한다면 데이터가 변경된다. 레디스 Sorted Set에서 동일한 member로 다른 score의 값을 저장하면 기존 데이터를 덮어씌우게 된다. 그렇다면, 과거의 데이터는 사라지게 된다.- 9초는 어떻게 기록할까?
11초는 10초보다 1이 더 높기 때문에
1이라고 표현하였지만 9초는 표현하기 어렵다. 만약score에-1이라고 표현한다면 0보다 더 낮기 때문에 제대로된 랭킹을 표시하기 어렵다.
이러한 문제를 해결하기 위해서 두 가지 데이터를 더 저장해주었다.
createdAt: 데이터 생성 시점type: 오차의 양수, 음수 표기(postive, negative)
예를 들어, 다음과 같이 데이터를 저장한다면
member: Danny:NEGATIVE:1766897311164
score: 1"Danny라는 닉네임을 가진 유저가 2025-12-28 13:48에 9초를 기록하였다." 라는 의미를 갖게 된다.
이러한 방식으로 member에는 nickname:type:timestamp 형태를 가지며 score에는 difference를 저장하여 랭킹 시스템을 구축하였다.
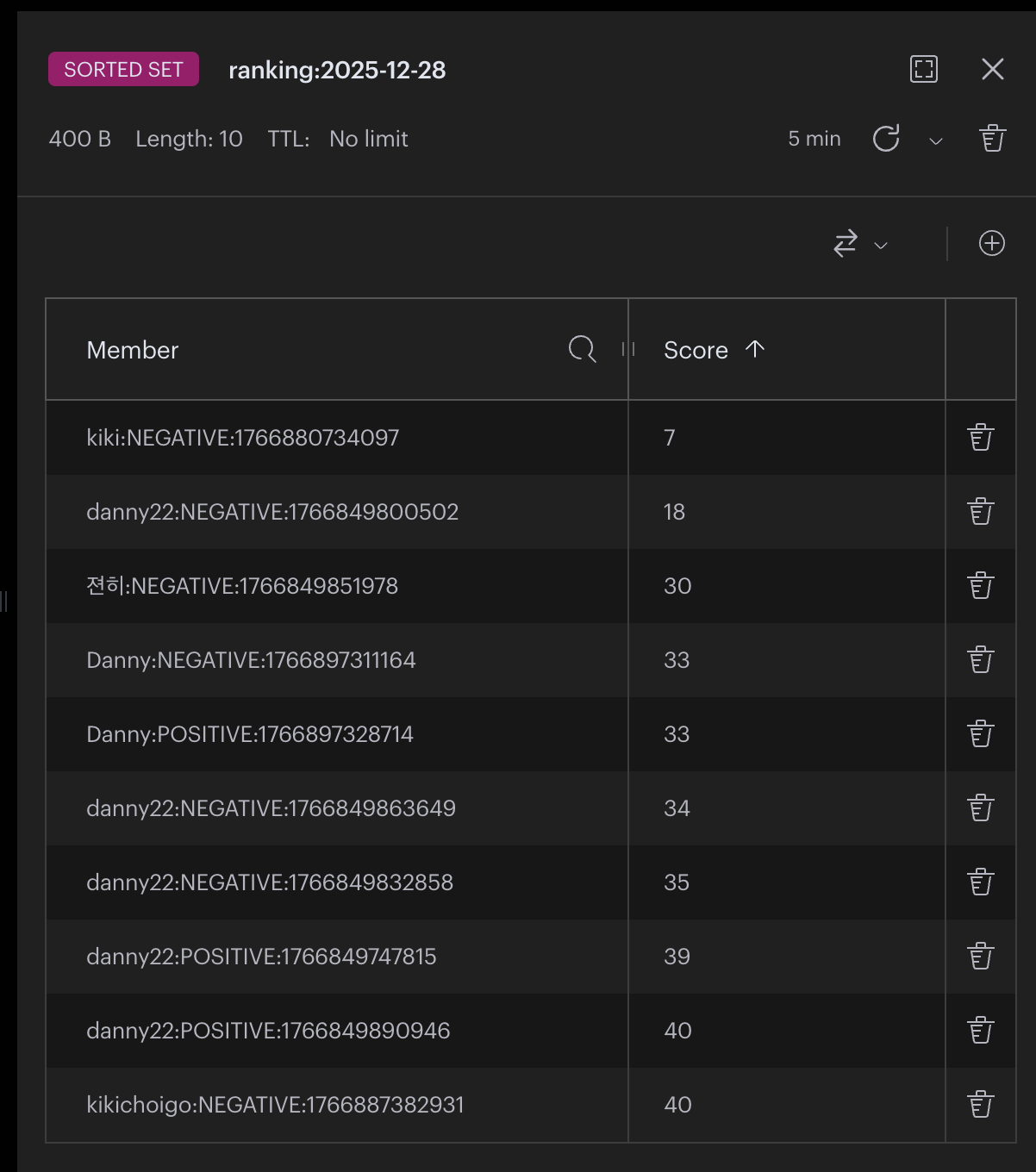
API
서버에서는 총 3개의 API만 필요하다.
| Method | Endpoint | Description |
|---|---|---|
| POST | /api/users | 사용자 닉네임 저장 |
| POST | /api/games | 사용자 타이머 기록 저장 및 랭킹 반영 |
| GET | /api/games | 랭킹 시스템 Top 10 조회 |
POST /api/users사용자가 닉네임을 입력하여 게임에 참여할 때 요청되며 레디스에 저장된 닉네임 리스트에 중복 검사를 진행한 후 데이터를 추가한다.POST /api/games사용자의 게임 기록을 저장할 때 요청되며 랭킹 시스템에 즉시 반영된다. 추가적으로 랭킹은 10위까지만 기록되기에 해당 순서가 초과되면 11번 순위부터의 데이터를 제거한다.GET /api/games랭킹 시스템에 기록된 10개의 데이터를 조회한다.
최종
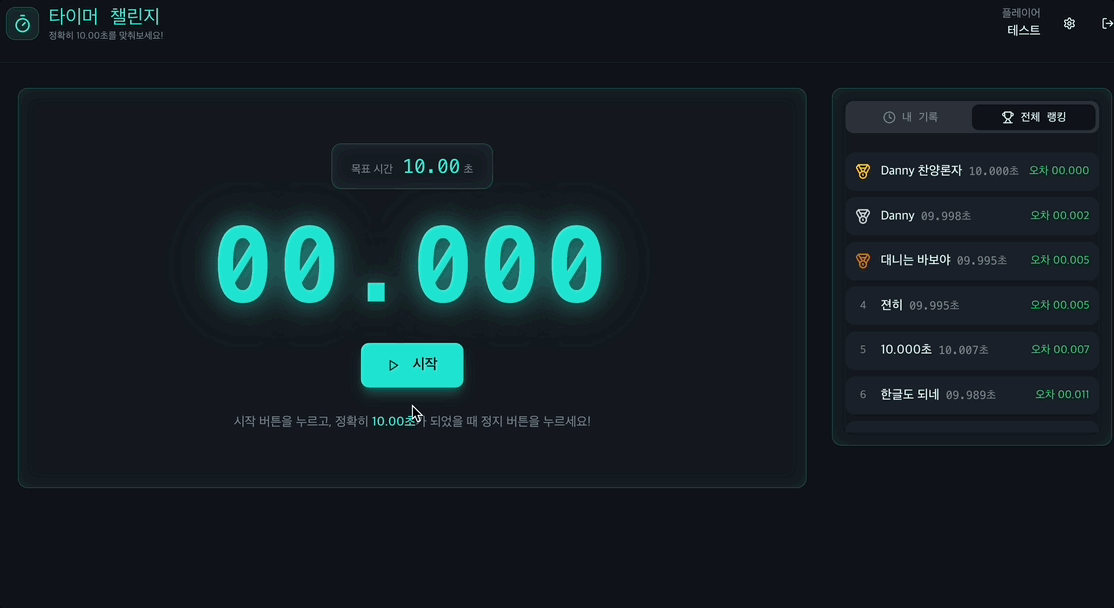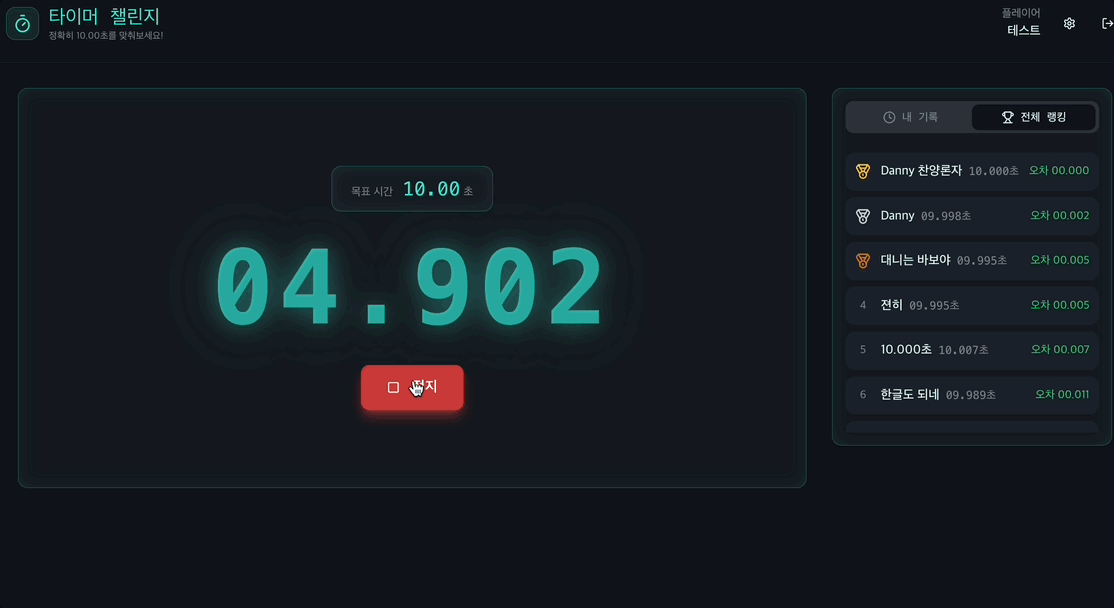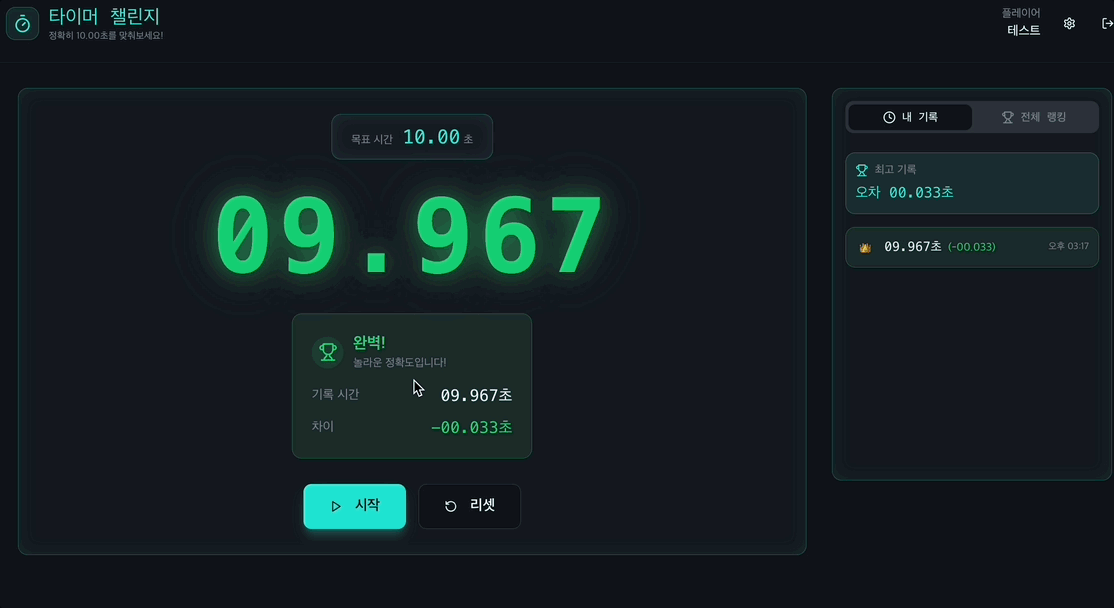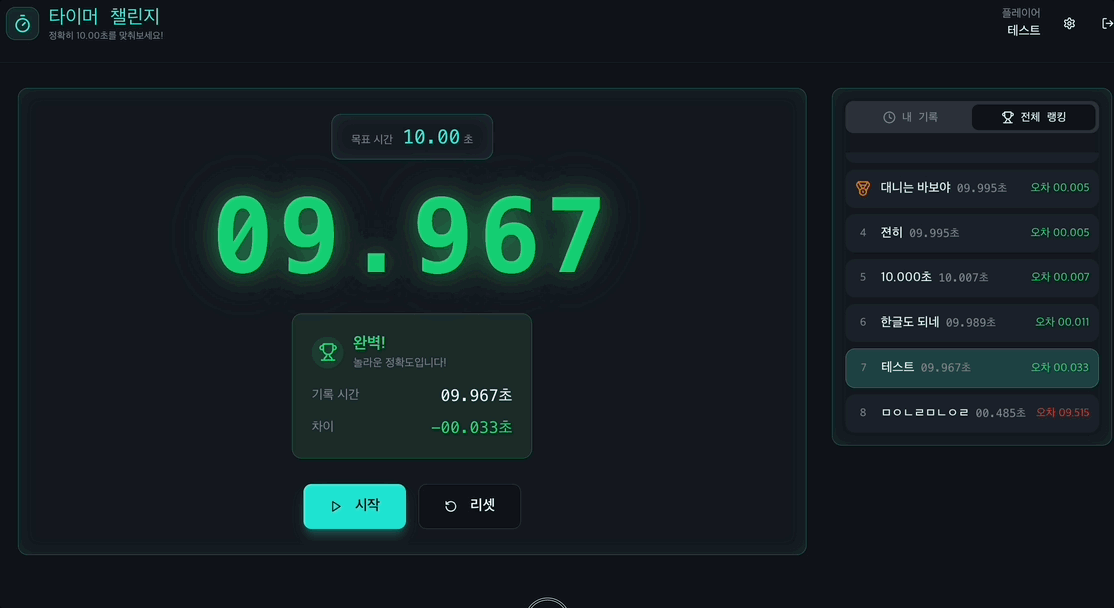
약 이틀 동안 간단히 만들고 여러 사람들에게 부탁드려 데이터를 수집하였지만 그 양이 너무 적었다..ㅎ 생각보다 게임이 지루해서 나조차도 많이 하지 않았다랄까...
아쉬웠던 점은 게임을 잘못 선정한 것 같다는 점이다. 재미없는 것을 둘째치고 타이머와 같은 기록은 축적되지 않기 때문에, 만약 일일 랭킹이 아닌 주간, 월간 랭킹으로 기능을 확장시킨다면 단순히 일일 랭킹에서 오차가 가장 적은 데이터만 추출하기만 하면 되거나 혹은 그러한 랭킹 데이터가 큰 의미가 없을 것이라 생각이 든다. (주간, 월간으로 갈수록 오차가 0인 데이터만 리스트로 나올 것이기에)
하지만 만약 스코어를 축적할 수 있는 게임으로 생성한다면 일일 데이터들을 종합하여 주간 랭킹으로 새로운 sorted set을 생성하여 표현해볼 수 있으며 더 나아가 월간, 년간으로도 데이터를 표시해볼 수 있는 경험을 할 수 있었을 것 같다. ZUNIONSTORE와 같은 명령어를 사용해본다면 기존의 sorted set들을 합산하여 새로운 sorted set을 만들어낼 수 있다.